Virginia Tech
Autoregressive world models generate worlds chunk by chunk as the user navigates. Once the camera moves past the reference frame, the unseen regions are populated by the model's priors, with no mechanism for the user to specify what should appear and where.
We introduce SPAWN (Swapping Pinned Anchor with Windowed iNjection), a training-free method for concept spawning. In autoregressive video models, the first slot of the context memory is pinned to the reference frame and acts as an anchor for every generated chunk. SPAWN replaces this anchor with a concept latent over a short window, then restores it. The concept persists in the rollout via the model's own memory. SPAWN works with either a concept image or a text prompt, and supports concepts from fine-grained entities to large landmarks.
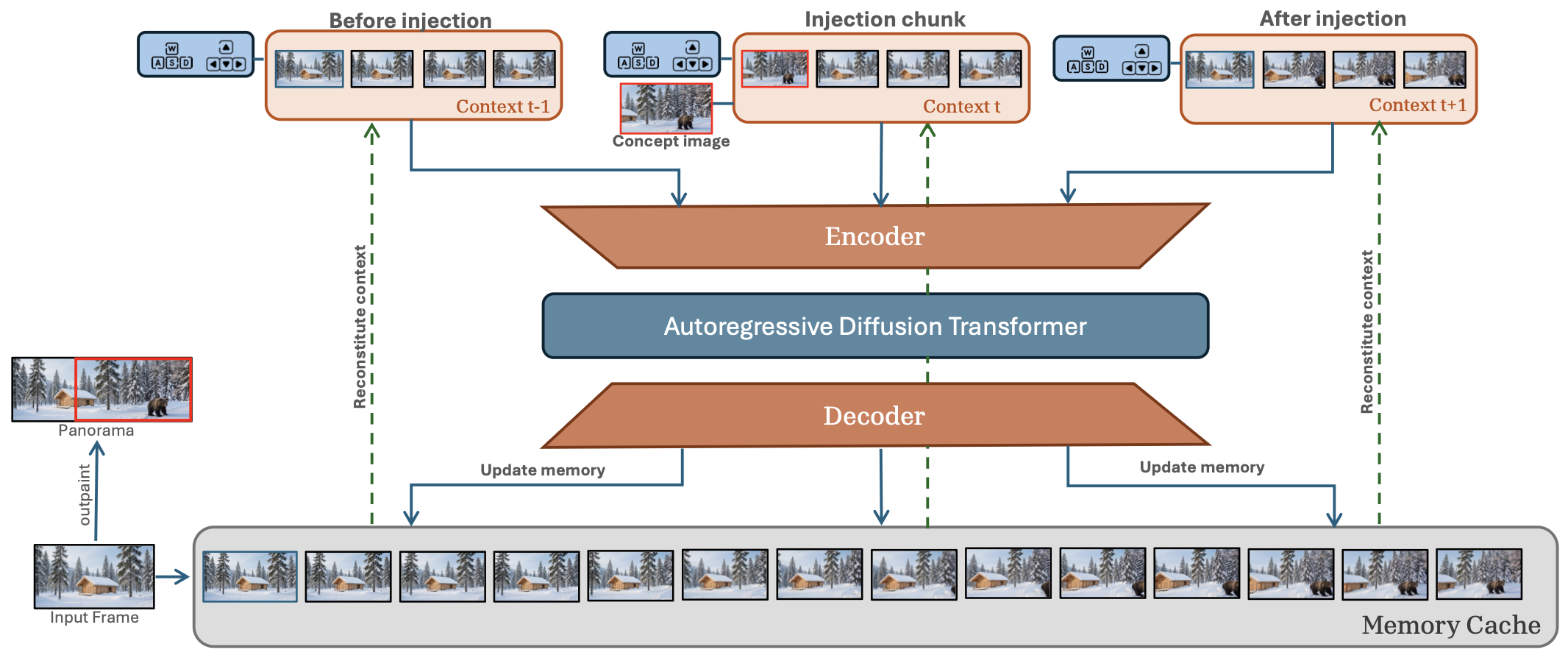
Method overview. At each rollout step, the context memory is reconstituted from the memory cache and passed through the encoder, autoregressive diffusion transformer, and decoder to produce the next chunk. At specified injection chunks, we replace the anchor slot of the context memory with a concept latent before encoding, which introduces the concept into the scene. Once the injection window ends, we restore the original anchor; even so, the concept persists in subsequent chunks. For clarity, the figure shows a reduced context size and a single replaced slot.



 to the right
to the right
 to the left
to the left
 above
above
@misc{akdemir2026zeroherotrainingfreecustom,
title={From Zero to Hero: Training-Free Custom Concept Spawning in World Models},
author={Kiymet Akdemir and Pinar Yanardag},
year={2026},
eprint={2606.02575},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2606.02575},
}